
To start with chemistry class, we’re studying the properties of substances (like density) and how to measure and report concentrations. So, I mixed up four solutions of table salt (NaCl) dissolved in water of different concentrations, and put a drop of food coloring into each one to clearly distinguish them. The class as a whole had to determine the densities of the solutions, thus learning how to use the scales and graduated cylinders.
However, for the students interested in doing a little bit more, I asked them to figure out the actual concentrations of the solutions.
One group chose to evaporate the liquid and measure the resulting mass in the beakers. Others considered separating the salt electrochemically (I vetoed that one based on practicality.
Most groups ended up choosing to mix up their own sets of standard solutions, measure the densities of those, and then use that data to determine the densities of the unknown solutions. Their data is shown at the top of this post.

The variability in their results is interesting. Most look like the result of systematic differences in making their measurements (different scales, different amounts of care etc.), but they all end up with curves where the concentration increases positively with density.
I showed the graph above to the class so we could talk about different sources of error, and how scientists will often compile the data from several different studies to get a better averaged result.
Then, I combined all the data and added a linear trend line so they could see how to do it using Excel (many of these students are in pre-calculus right now so it ties in nicely):
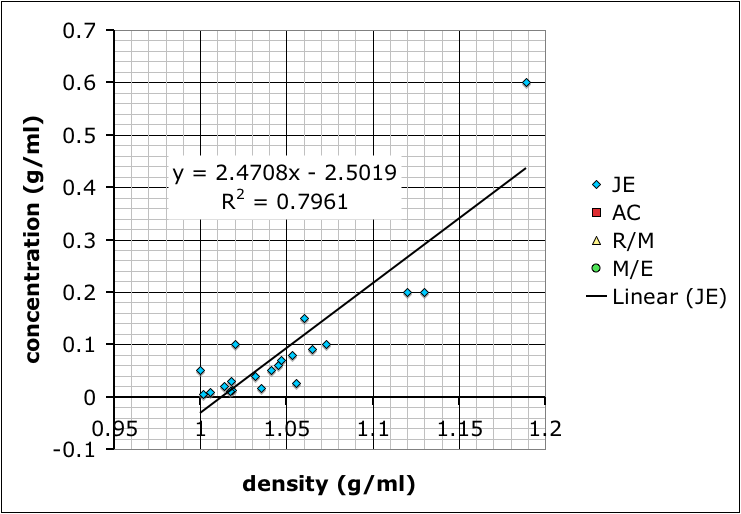
What we have not talked about yet–I hope to tomorrow–is how the R-squared value, which gives the goodness of the fit of the trend line to the data, is more a measure of precision rather than accuracy. It does say something about how internally consistent the data are, but not necessarily if the result is accurate.
It’s also useful to point out that the group with the best R-squared value is the one with only two data points because two data points will necessarily give a perfectly straight line. However, the groups that made more solutions might not have as good of an R-squared value, but, because of the multiple measurements, probably have more reliable results.
As for which group got the most accurate result: I added in some data I found by googling–it came off a UCSD website with no citation so I’m going to need to find a better reference. Comparing our data to the reference we find that team AC (the red squares) best match:
