Once you start R you’ll need to figure out which directory you’re working in:
> getwd()On a Windows machine your default working directory might be something like:
[1] "C:/Users/username"On OSX or Linux you’ll get something like:
[1] "/Users/username" To get to the directory you want to work in use setwd(). I’ve put my files into the directory: “/Users/lurba/Documents/TFS/Stats/COVID”
To get there from the working directory above I could enter the full path above, or just the relative path like:
> setwd("TFS/Stats/COVID")Now my data is in the file named “04-20-2020.csv” (from the John Hopkins Covid data repository on github) which I’ll read in with:
> mydata <- read.csv("04-20-2020.csv")This creates a variable named “mydata” that has the information in it. I can see the column names by using:
> colnames(mydata)which gives:
[1] "Province_State" "Country_Region" "Last_Update"
[4] "Lat" "Long_" "Confirmed"
[7] "Deaths" "Recovered" "Active"
[10] "FIPS" "Incident_Rate" "People_Tested"
[13] "People_Hospitalized" "Mortality_Rate" "UID"
[16] "ISO3" "Testing_Rate" "Hospitalization_Rate"Let’s take a look at the summary statistics for the number of confirmed cases, which is in the column labeled “Confirmed”:
> summary(mydata$Confirmed) Min. 1st Qu. Median Mean 3rd Qu. Max.
317 1964 4499 15347 13302 253060 This shows that the mean is 15, 347 and the maximum is 253,060 confirmed cases.
I’m curious about which state has that large number of cases, so I’m going to print out the columns with the state names (“Province_State”) and the number of confirmed cases (“Confirmed”). From our colnames command above we can see that “Province_State” is column 1, and “Confirmed” is column 6, so we’ll use the command:
> mydata[ c(1,6) ]The “c(1,6)” says that we want the columns 1 and 6. This command outputs
Province_State Confirmed
1 Alabama 5079
2 Alaska 321
3 American Samoa 0
4 Arizona 5068
5 Arkansas 1973
6 California 33686
7 Colorado 9730
8 Connecticut 19815
9 Delaware 2745
10 Diamond Princess 49
11 District of Columbia 2927
12 Florida 27059
13 Georgia 19407
14 Grand Princess 103
15 Guam 136
16 Hawaii 584
17 Idaho 1672
18 Illinois 31513
19 Indiana 11688
20 Iowa 3159
21 Kansas 2048
22 Kentucky 3050
23 Louisiana 24523
24 Maine 875
25 Maryland 13684
26 Massachusetts 38077
27 Michigan 32000
28 Minnesota 2470
29 Mississippi 4512
30 Missouri 5890
31 Montana 433
32 Nebraska 1648
33 Nevada 3830
34 New Hampshire 1447
35 New Jersey 88722
36 New Mexico 1971
37 New York 253060
38 North Carolina 6895
39 North Dakota 627
40 Northern Mariana Islands 14
41 Ohio 12919
42 Oklahoma 2680
43 Oregon 1957
44 Pennsylvania 33914
45 Puerto Rico 1252
46 Rhode Island 5090
47 South Carolina 4446
48 South Dakota 1685
49 Tennessee 7238
50 Texas 19751
51 Utah 3213
52 Vermont 816
53 Virgin Islands 53
54 Virginia 8990
55 Washington 12114
56 West Virginia 902
57 Wisconsin 4499
58 Wyoming 317
59 Recovered 0
Looking through, we can see that New York was the state with the largest number of cases.
Note that we could have searched for the row with the maximum number of Confirmed cases using the command:
> d2[which.max(d2$Confirmed),]Merging Datasets
In class, we’ve been editing the original data file to add a column with the state populations (called “Population”). I have this in a separate file called “state_populations.txt” (which is also a comma separated variable file, .csv, even if not so labeled). So I’m going to import the population data:
> pop <- read.csv("state_population.txt")Now I’ll merge the two datasets to add the population data to “mydata”.
> mydata <- merge(mydata, pop)Graphing (Histograms and Boxplots)
With the datasets together we can try doing a histogram of the confirmed cases. Note that there is a column labeled “Confirmed” in the mydata dataset, which we’ll address as “mydata$Confirmed”:
> hist(mydata$Confirmed)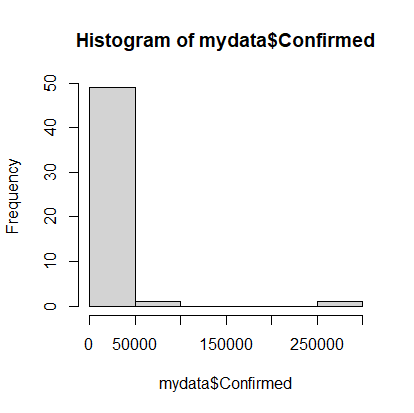
Note that on April 20th, most states had very few cases, but there were a couple with a lot of cases. It would be nice to see the data that’s clumped in the 0-50000 range broken into more bins, so we’ll add an optional argument to the hist command. The option is called breaks and we’ll request 20 breaks.
> hist(mydata$Confirmed, breaks=20)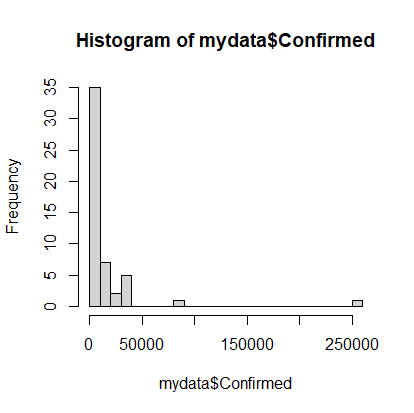
Calculations (cases per 1000 population)
Of course, simply looking at the number of cases in not very informative because you’d expect, with all things being even, that states with the highest populations would have the highest number of cases. So let’s calculate the number of cases per capita. We’ll multiply that number by 1000 to make it more human readable:
> mydata$ConfirmedPerCapita1000 <- mydata$Confirmed / mydata$Population * 1000Now our histogram would look like:
> hist(mydata$ConfirmedPerCapita1000, breaks=20)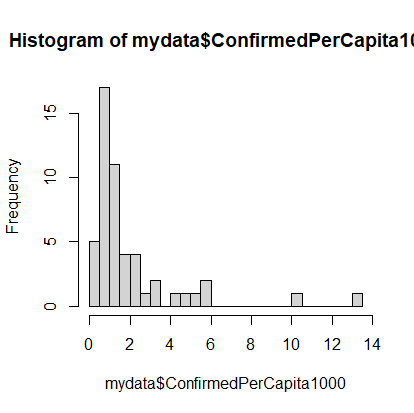
The dataset still has a long tail, but we can see the beginnings of a normal distribution.
The next thing we can do is make a boxplot of our cases per 1000 people. I’m going to set the range option to zero so that the plot has the long tails:
> boxplot(mydata$ConfirmedPerCapita1000, range=0)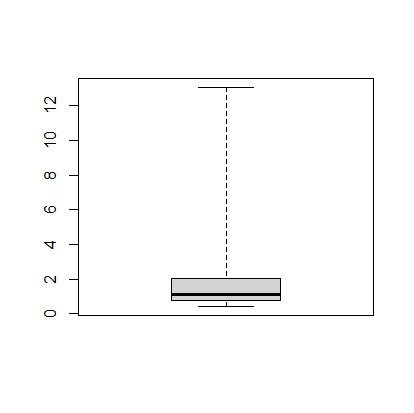
The boxplot shows, more or less, the same information in the histogram.
Finding Specific Data in the Dataset
We’d like to figure out how Missouri is doing compared to the rest of the states, so we’ll calculate the z-score, which tells how many standard deviations you are away from the mean. While there is a built in z-score function in R, we’ll first see how we can use the search and statistics methods to find the relevant information.
First, finding Missouri’s number of confirmed cases. To find all of the data in the row for Missouri we can use:
> mydata[mydata$Province_State == "Missouri",]which gives something like this. It has all of the data but is not easy to read.
Province_State Population Country_Region Last_Update Lat
26 Missouri 5988927 US 2020-04-20 23:36:47 38.4561
Long_ Confirmed Deaths Recovered Active FIPS Incident_Rate People_Tested
26 -92.2884 5890 200 NA 5690 29 100.5213 56013
People_Hospitalized Mortality_Rate UID ISO3 Testing_Rate
26 873 3.395586 84000029 USA 955.942
Hospitalization_Rate ConfirmedPerCapita1000
26 14.82173 0.9834817To extract just the “Confirmed” cases, we’ll add that to our command like so:
> mydata[mydata$Province_State == "Missouri",]$Confirmed[1] 5890Which just gives the number 5890. Or the “ConfirmedPerCapita1000”:
> mydata[mydata$Province_State == "Missouri",]$ConfirmedPerCapita1000
[1] 0.9834817This method would also be useful later on if we want to automate things.
z-score
We have the mean from when we did the summary command, but there’s also a mean command.
> mean(mydata$ConfirmedPerCapita1000)
[1] 2.006805Similarly you can get the standard deviation with the sd function.
> sd(mydata$ConfirmedPerCapita1000)
[1] 2.400277We can now calculate the z-score for Missouri:

which gives a results of:

So it looks like Missouri was doing reasonable well back in April, at least compared to the rest of the country.