Since we’re working on geometry this cycle, I thought it would be an interesting exercise to think about how we could use geometry to think about how the strength of tsunamis decreases with distance from the source.
Of course, we’ll have to do this using some intense simplification so we can actually apply the tools we have available. The first is to approximate the tsunami as a circular wall of water centered on the epicenter of the earthquake.

This lets us figure out the volume of the wave pretty easily because we know that the volume of a cylinder is:
(1)

The size of the circular water wall we approximate from the reports from Japan. The maximum height of the wave at landfall was somewhere in the range of 14 m along the northern Japanese coast, which was about 80 km from the epicenter. Just as a wild guess, I’m assuming that the “effective” width of the wave is 1 km.
Typically, in deep water, a tsunami can have a wavelength greater than 500 km (Nelson, 2010; note that our width is half the wavelength), but a wave height of only 1 m (USSRTF). When they reach the shallow water the wave height increases. The Japanese tsunami’s maximum height was reportedly about 14 m.
At any rate, we can figure out the volume of our wall of water by calculating the volume of a cylinder with the middle cut out of it. The radius of our inner cylinder is 80 km, and the radius of the outer cylinder is 80 km plus the width of the wave, which we say here is 1 km.
Calculating the volume of the wave
However, for the sake of algebra, we’ll call the radius of the inner cylinder, ri and the width of the wave as w. Therefore the inner cylinder has a volume of:
(2)

So the radius of the outer cylinder is the radius of the inner cylinder plus the width of the wave:
(3)

which means that the volume of the outer cylinder is:
(4)

So now we can figure out the volume of the wave, which is the volume of the outer cylinder minus the volume of the inner cylinder:
(5)

(6)

Now to simplify, let’s expand the first term on the right side of the equation:
(7)

Now let’s collect terms:
(8)

Take away the inner parentheses:
(9)

and subtract similar terms to get the equation:
(10)

Volume of the wave
Now we can just plug in our estimates of width and height to get the volume of water in the wave. We’re going to assume, later on, that the volume of water does not change as the wave propagates across the ocean.
(11)

rearrange so the coefficients are in front of the variables:
(12)

So, at 80 km, the volume of water in our wave is:
(13)

(14)

Height of the Tsunami
Okay, now we want to know what the height of the tsunami will be at any distance from the epicenter of the earthquake. We’re assuming that the volume of water in the wave remains the same, and that the width of the wave also remains the same. The radius and circumference will certainly change, however.
We take equation (10) and rearrange it to solve for h by first dividing by rearranging all the terms on the right hand side so h is at the end of the equation (this is mostly for clarity):
(15)

Now we can divide by all the other terms on the right hand side to isolate h:
(16)

so:
(17)

which when reversed looks like:
(18)

This is our most general equation. We can use it for any width, or radius of wave that we want, which is great. Anyone else who wants to calculate wave heights for other situations would probably start with this equation (and equation (15)).
Double checking our algebra
So we can now figure out the height of the wave at any radius from the epicenter of the earthquake. To double check our algebra, however, let’s plug in the volume we calculated, and the numbers we started off with, and see if we get the same height (14 m).
First, we’ll use all our initial approximations so we get an equation with only two variables: height (h) and radial distance (ri). Remember our initial conditions:
w = 1000 m
ri = 80,000 m
hi = 14 m
we used these numbers in equation (10) to calculate the volume of water in the wave:
Vw = 7081149841 m3
Now using these same numbers in equation (18) we get:
(19)

which simplifies to:
(20)

So, to double-check we try the radius of 80 km (80,000 m) and we get:
h = 14 m
Aha! it works.
Across the Pacific
Now, what about Hawaii? Well it’s about 6000 km away from the earthquake, so taking that as our radius (in meters of course), in equation (20) we get:
(21)

which is:
h = 0.19 m
This is just 19 cm!
All the way across the Pacific, Lima, Peru, is approximately 9,000 km away, which, using equation (20) gives:
h = 0.13 m
So now I’m curious about just how fast the 14 meters drops off to less than 20 cm. So I bring up Excel and put together a spreadsheet of tsunami height at different distances. Plot on a graph we get:

So the height of the tsunami drops off relatively fast. Within 1000 km of the earthquake the height has dropped by 90%.
How good is this model
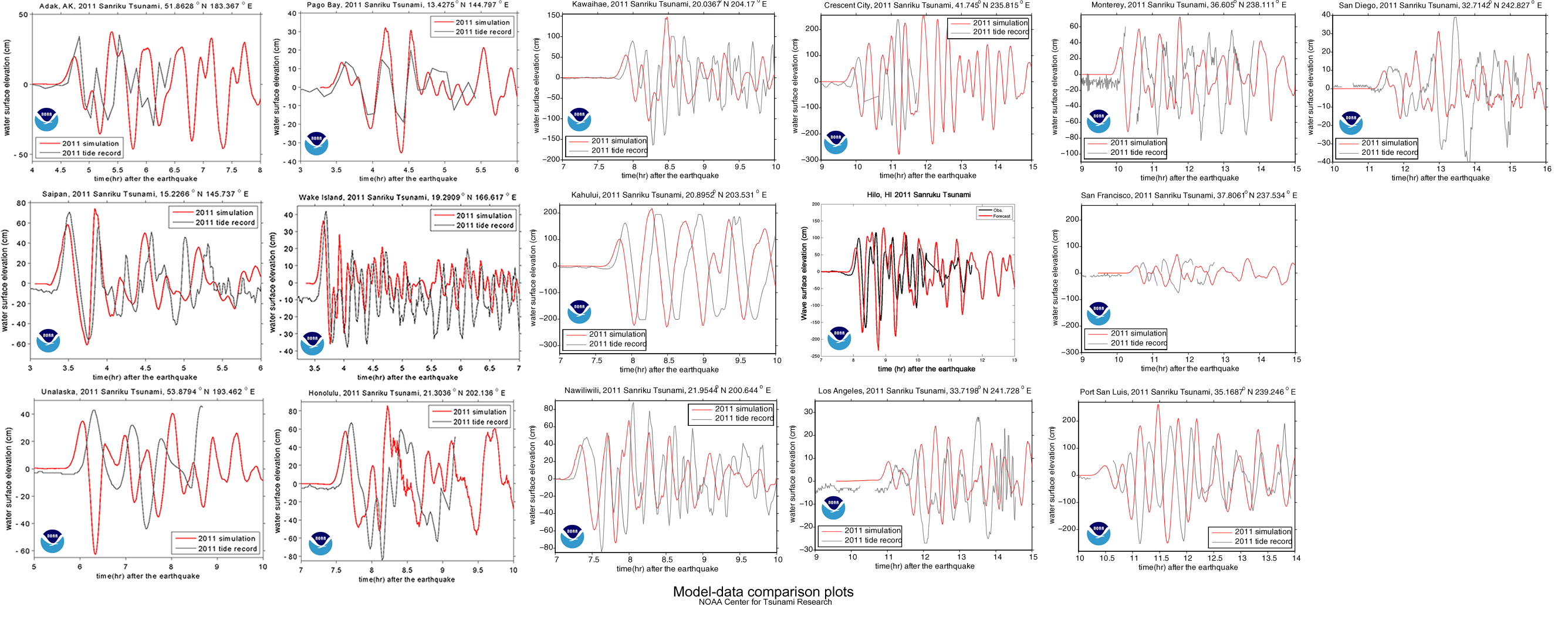
This is all very nice, a cute little exercise in algebra, but is it useful? Does it come anywhere close to reality? We can check by comparing it to actual measurements; the same ones used by NOAA to compare to their model (see here).


The graph shows a maximum height of about 60 cm, which is about three times larger than our model. NOAA’s estimate is within 20% of the actual maximum heights, but they’ve spent a bit more time on this problem, so they should be a little better than us. You can find all the gruesome details on NOAA’s Center for Tsunami Research site’s Tsunami Forecasting page.
Notes
1. The maximum height of a tsunami depends on how much up-and-down motion was caused by the earthquake. ScienceDaily reports on a 2007 article that tried to figure out if you could predict the size of a tsunami based on the type of earthquake that caused it.
2. Using buoys in the area, NOAA was able to detect and warn about the Japanese earthquake in about 9 minutes. How do they know where to place the buoys? Plate tectonics.

Update
The equations starting with (7) did not have the 2 on the riw term. That has been corrected. Note that the numerical calculations were correct so they have not changed. – Thanks to Spencer and Claude for helping me catch that.













{kind=link}